Substrate off-chain workers: Secure and efficient computing-intensive tasks
Many blockchain developers, enthusiasts and technologists often get the question, "what can we put on a blockchain?" We can cite the early…
Many blockchain developers, enthusiasts and technologists often get the question, "what can we put on a blockchain?" We can cite the early examples of a currency such as Bitcoin or decentralized applications and smart contracts built on Ethereum. We can also showcase even more recent, specialized examples like the UN World Food Programme's Building Blocks project that gives refugees cash-for-food in places where banks and payment systems are unreliable, or even supply tracking of pharmaceuticals across the U.S. using the Mediledger Network. Parity Technologies has built the technology with Substrate and surrounding tech stack to make these new blockchains possible to design and deploy for any project or enterprise, and our experience has shown us the possibilities of what can be put on a blockchain.
But what shouldn't be on a blockchain? What kinds of systems and features are too computationally expensive to be processed on-chain? Here's where Parity has been working on advancing the standard of how work should be done off-chain. Substrate's Off-chain Workers allows the processes that are too intensive or data that's too massive to be handled by specialized nodes on the network, all while storing the code for how to do the work on-chain to ensure participants are automatically kept up to date with the latest logic that their chain dictates.
What kind of work is best performed off-chain?
Perhaps answering the opposite questions is better: on-chain logic is processed by the entire network. Therefore each computational operation that is required to process a transaction is expensive (you're paying for everyone to execute it and to store the results), slow (everyone must take time to agree on the answer) and fully deterministic (everyone must have all, exactly equivalent, data in order to calculate the result). Off-chain logic is therefore not only suited, but rather needed, whenever the computation is significant (like sophisticated democratic mechanisms such as delegated voting), the storage footprint is large (such as archiving staking information which may be required at a later time), where time is of the essence, where elements of the computation must remain private (such as nodes being able to manage their own secrets for eventual identification) or where the operations to be done are necessarily non-deterministic or otherwise localized (such as passing in random numbers, fetching data from a website or calling an external RPC).
All of these examples and more would enrich many blockchains and decentralized networks and make them more useful to a myriad of new markets and participants, but there have been problems in establishing these services, even off-chain.
In traditional off-chain environments, there are a couple major pain points for secure off-chain computation:
- Off-chain mechanisms are an independent process, and as such they require their own maintenance that needs to be coordinated separately from the blockchain itself. This creates large overhead for the network as a whole. It takes a lot of extra effort and communication to maintain and update off-chain functions. New requirements may be needed or bugs are found and must be fixed.
- Off-chain computation has also traditionally communicated over RPC, which can be slow and unreliable. Querying the state of a blockchain and getting all the necessary headers is difficult and unreliable. Sometimes if the state you're querying is too large, it may be unfeasible for the nodes on the network to keep up.
Even if those pain points are somehow mitigated, submitting transactions with that data requires a lot of work and may prove to be too expensive for the value it provides.
Introducing Substrate off-chain workers
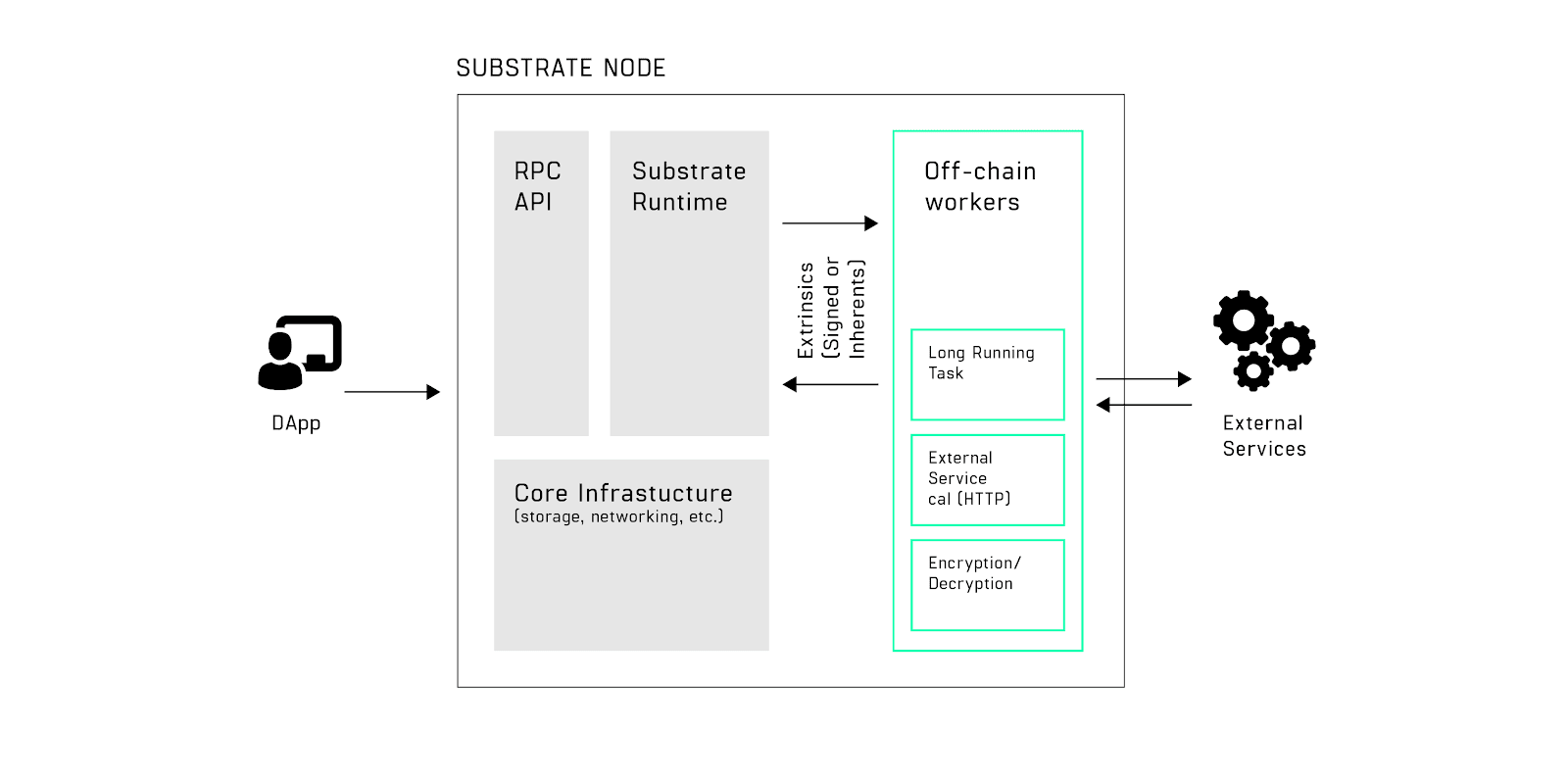
To make off-chain data integration secure and more efficient, Substrate provides off-chain workers. The off-chain worker subsystem allows execution of long-running and possibly non-deterministic tasks (e.g. web requests, encryption/decryption and signing of data, random number generation, CPU-intensive computations, enumeration/aggregation of on-chain data, etc.) which could otherwise require longer than the block execution time.
The code for the off-chain workers is stored on-chain, and has access to the on-chain environment, but is never executed as part of block-processing. Off-chain workers make it easy to run the correct code and allow longer running tasks to be performed without holding up the blockchain. But, the on-chain code allows verification mechanisms, such as voting, averaging, and challenging to be implemented in the state-transition function of the blockchain it is running on. It is up to the blockchain/oracle network designer and those running nodes on the network to agree on exactly who should be doing what, when, and the rewards and punishments for participants.
Want to see a walkthrough of the code? Check out this callback example.
If you want traditional oracles to be run by multiple nodes and authorities on your network, this is very difficult to achieve, especially if you want to update them to new versions. Off-chain workers solve this issue by publishing this piece of infrastructure across the network, allowing nodes to be aware when they are out of date. This makes running oracle networks much easier to deploy and maintain over time as these networks grow in size, complexity and sophistication.
Because they are a part of the runtime code, instead of running a separate process, they are run by Substrate itself in the same way as the state transition function is run on every block import - they are either executed in the sandboxed WebAssembly (Wasm) environment, or if the on-chain code version matches the node implementation, they benefit from performance improvements running natively.
Off-Chain Worker APIs
Since off-chain workers are running in a sandboxed environment, they can only access a limited set of APIs for security reasons. They do have full access to any on-chain state and have additional capabilities to communicate with the external world via extended set of APIs.
- Local Storage. An additional, local key-value database shared between all off-chain workers.
- HTTP requests API. A fully-featured HTTP client allowing to access and fetch data from external services.
- A secure, local entropy source for random number generation.
- Access to local node precise time and ability to sleep/resume work.
- Access to the local keystore to sign and verify statements or transactions.
- Ability to submit transactions (either signed or unsigned) back on-chain to publish computation results.
Note: Some of these APIs are still under development. More information and usage documentation will be published as and when the APIs are available for use.
Get started on playing with Substrate off-chain workers by checking out the example pallet, learn by example with this walkthrough of a callback, or talking to the developers in the Substrate technical channel.